Projects
A list of exciting projects that I have been a part of! Will be updated as and when possible.
publications

|
Sindhu B Hegde*, K R Prajwal*, Taien Kwon, Andrew Zisserman ICCV, 2025 (Oral Presentation) pdf / code / project page / 🤗 dataset Learn semantic co-speech gesture representations by associating gesture movements with speech and text. The learned gesture representations can be used to perform multiple downstream tasks such as cross-modal retrieval, spotting gestured words, and identifying who is speaking solely from gestures. |

|
K R Prajwal*, Sindhu B Hegde*, Andrew Zisserman ICASSP, 2025 (Oral Presentation) pdf / code / project page / 🤗 dataset / demo video Introduce MultiVSR - a new large-scale public dataset for multilingual visual speech recognition. MultiVSR comprises ~12,000 hours of video data paired with word-aligned transcripts from 13 languages. Also design a multi-task architecture, which can simultaneously perform two tasks: (i) language identification and (ii) visual speech recognition from silent lip videos. |

|
Sindhu B Hegde, Andrew Zisserman BMVC, 2023 (Oral Presentation) arXiv / code / project page / 🤗 demo / demo video Introduce a new synchronisation task -> Gesture-Speech Synchronisation: Identifies if the person's gestures and speech are in-sync or not. The learned representations can be used to determine who is speaking in a multi-speaker scenario. |

|
Sindhu B Hegde*, Rudrabha Mukhopadhyay*, Vinay P Namboodiri, C. V. Jawahar ACM-MM, 2022 arXiv / code / project page Super-resolve extremely low-resolution videos (eg., 8x8 pixels) to obtain realistic, high-resolution outputs (256x256 pixels). Upsamples the videos at a scale-factor of 32x for the first time!. |
|
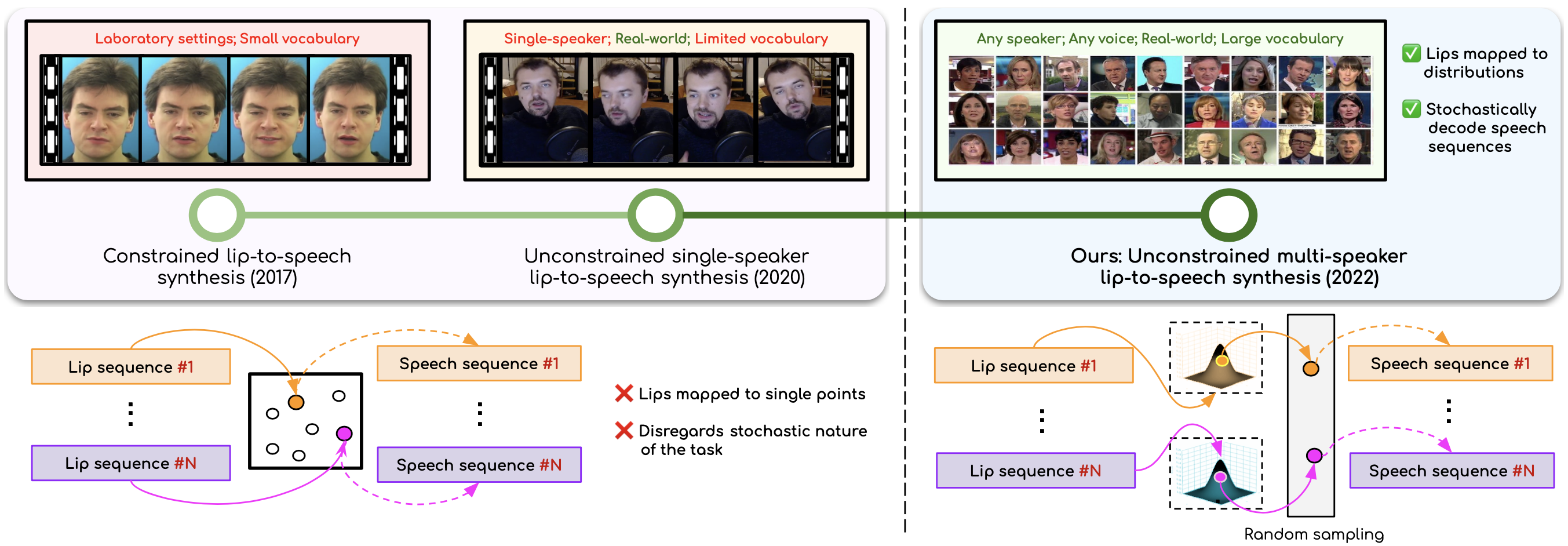
Sindhu B Hegde*, K R Prajwal*, Rudrabha Mukhopadhyay*, Vinay P Namboodiri, C. V. Jawahar ACM-MM, 2022 arXiv / code / project page Generates speech for silent talking face videos for any speaker in-the-wild! One of the first models to work for arbitrary speakers, with no explicit costraints in the domain or vocabulary. |
|
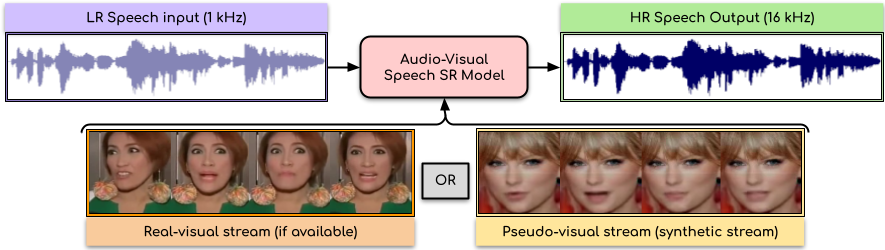
Rudrabha Mukhopadhyay*, Sindhu B Hegde*, Vinay P Namboodiri, C. V. Jawahar BMVC, 2021 (Oral Presentation) pdf / presentation / project page An audio-visual model to super-reolve very low-resolution speech signals (e.g., 1kHz) & generate high-quality speech (16kHz). Works even if the real-visual stream is unavailable/corrupted using the proposed pseudo-visual approach! |

|
Sindhu B Hegde*, K R Prajwal*, Rudrabha Mukhopadhyay*, Vinay P Namboodiri, C. V. Jawahar WACV, 2021 arXiv / demo video / presentation / code / project page A new paradigm for speech enhancement that works effectively in unconstrained, high-noise, real-world environments. A hybrid approach to hallucinate the visual stream using only the noisy speech as input. |

|
Parul Kapoor, Rudrabha Mukhopadhyay, Sindhu B Hegde, Vinay P Namboodiri, C. V. Jawahar INTERSPEECH, 2021 arXiv / demo video / code / project page Generated continuous sign-language videos solely from speech segments for the first time. Also curated and released the first Indian Sign Language (ISL) dataset comprising speech annotations, transcripts & sign-language videos. |

|
Rudrabha Mukhopadhyay*, K R Prajwal*, Sindhu B Hegde*, Vinay P Namboodiri, C. V. Jawahar ICPR Demonstrations, 2020 demo video / writeup Extensively explore the correlation between vision and speech modalities, specifically the speech and lip movements. |
implementations
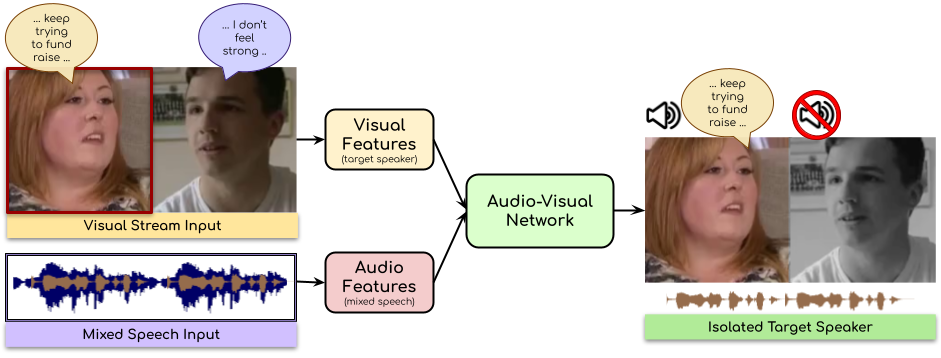
|
code / colab / presentation Separate the two speakers talking simultaneously in a cocktail-party like situation. An audio-visual model to enhance & isolate the speech of the target speaker. Papers referred:(1) The Conversation: Deep Audio-Visual Speech Enhancement (2) Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation |
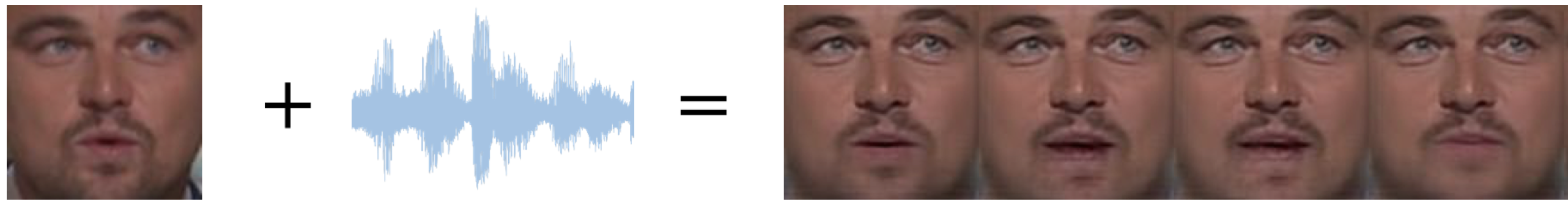
|
code Generate a talking-face video from the still image of the target identity & the corresponding speech segment. Works for unseen faces & audios! Papers referred:(1) You said that? (2) Towards Automatic Face-to-Face Translation |